There is a paper that has been quietly circulating in ML research circles that I think deserves more attention. It is called Nested Learning, and it proposes something radical: that every major architecture in deep learning — RNNs, Transformers, state-space models, even the optimizer itself — is secretly the same thing, viewed from different angles.
The Problem with How We Think About Architecture
When most people think about neural network architectures, they think about layers. You stack a self-attention block on top of a feedforward network, wrap it in residual connections, repeat 96 times, and call it GPT-4. The architecture is the recipe. The optimizer is separate. Training is something that happens to the architecture.
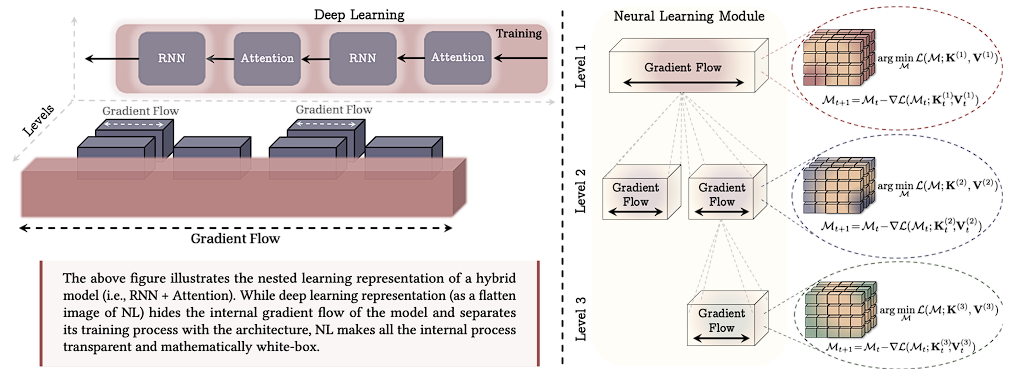
Nested Learning (NL) says this view is wrong — not slightly off, but fundamentally backward. The architecture is the optimizer. Or more precisely: what we call an "architecture" is a set of nested optimization processes running at different frequencies, each with its own objective and context window.

Uniform and Reusable Structure
The brain has a remarkable property: its basic computational unit — the cortical column — is essentially the same whether it's processing vision, language, or motor control. Neuroplasticity works precisely because this structure is uniform and reusable. The brain doesn't rewire itself with new types of neurons; it rewires the connections between the same building blocks.
In NL, architectures are decomposed into a set of neurons (i.e., linear or locally deep MLPs), each of which with its own context flow and objective. This design provides a uniform and reusable structure for learning.
This is the first key insight. Once you decompose any architecture into its NL form, you see the same thing everywhere: feedforward networks being optimized with respect to some local objective, over some local context. The apparent heterogeneity of modern architectures is an illusion.
Multi Time Scale Update
The brain doesn't update all its neurons at the same speed. Delta waves (0.5–4 Hz) govern deep slow consolidation. Gamma waves (30–100 Hz) handle rapid local processing. There is no single centralized clock. Earlier layers update quickly in response to immediate inputs; later layers integrate information over much longer time scales.
In NL, parameters in each "level" are updated with their own specific frequency and does not rely on a single centralized clock. The HoPE's design allows the earlier layers update their activity quickly in high-frequency cycles, whereas later layers integrate information over longer, slower cycles.
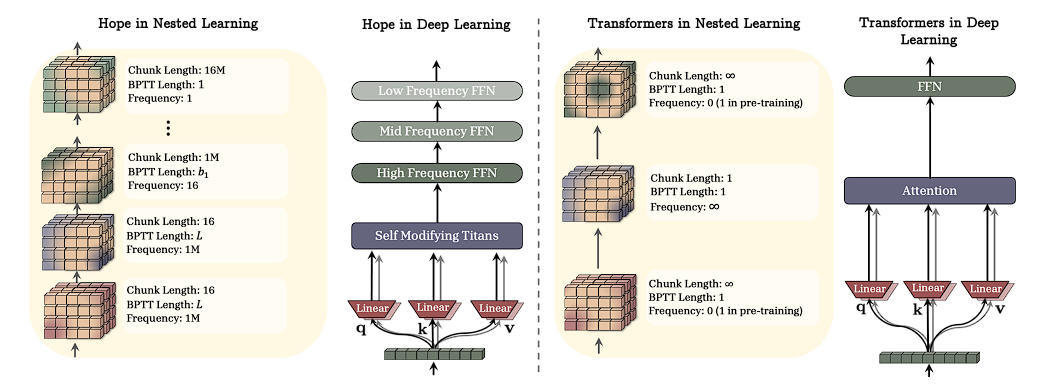
This is where NL becomes genuinely strange and interesting. The standard Transformer updates all its parameters at the same rate — one gradient step per forward pass. But in the NL framework, a Transformer is actually doing something more subtle: the attention mechanism is updating a "fast memory" at frequency ∞ (every token), while the FFN weights update slowly (only during the outer training loop).
Everything is the Same Thing
Here is the claim that initially sounds too strong to be true, but becomes more convincing the longer you think about it: RNNs, Transformers, and SSMs are all the same optimization process, parameterized differently.
An RNN is a level-1 NL module: it maintains a hidden state (fast memory) that it updates at every timestep using its recurrence weights (slow memory). The recurrence is the optimizer; the weights are the model being optimized.
A Transformer's attention mechanism, viewed through NL, is solving a different optimization: it finds the optimal "memory state" for the entire context at once, rather than incrementally. This is why attention has infinite context but quadratic cost — it's re-solving the whole optimization problem from scratch at every layer.
This is exactly softmax attention. It's finding the optimal memory state for the entire context at once, rather than incrementally updating parameters. The formula that underlies every modern LLM is, in the NL view, just one particular solution to a particular memory optimization problem.
Why This Matters
The standard deep learning framework has a hidden bug: catastrophic forgetting. When you fine-tune a model on new data, it overwrites old knowledge. This happens because everything runs at the same frequency — there's no slow consolidation, no long-term memory that resists rapid updates.
The promise of Nested Learning is that we can build AI systems that don't suffer from this amnesia, systems that can form new long-term memories gradually, consolidate experiences across time scales, and truly learn continually without catastrophic forgetting.
But more than that, NL suggests that the distinction between "architecture" and "optimizer" is artificial. They're both parts of the same nested system. The question isn't "What layers should I stack?" but "What optimization processes should I nest, and at what frequencies?"
This is a paradigm shift in the Thomas Kuhn sense — not just new techniques, but a new way of seeing the entire field. Whether NL becomes the dominant framework or just a useful perspective, it's asking the right questions.
And asking the right questions, as always, is half the battle.
Will cover the HoPE architecture in the next part.